
As I’m building my AS3 game prototype, one question I’m constantly debating is whether I should use Box2DFlash or Nape as my physics engine of choice.
This prototype is heavily focused on realistic physics, so the debate has been intense. On the one hand, Box2D is a tried and proven solution, one that’s easy to find references and tutorials for online, and one that has a good number of support tools available (most notably the R.U.B.E. editor, which I started using recently to design my game prototype’s levels). On the other hand, Nape has a more AS3-focused API, and has faster performance. However, Nape doesn’t support some features I was using extensively on Box2D (edges and lines). At the same time, the AS3 version of Box2D is lagging behind the original (C) version, as it lacks some important features that I needed too.
I could go on and on. But I digress. That’s not the point of this post.
While deciding on whether to mess around Box2D (to add the features I needed) or with Nape (to work around its limitations), I ended up spending so much time adding the missing Box2D features to the AS3 version (especially EdgeShape and ChainShape, which are still not working well on my build) that I decided to try and do it the other way around, getting a Nape-based prototype to load a R.U.B.E. scene while at the same time emulating some of Box2D’s elements and their properties.
This solution ended up being more elegant than I thought it would be. The result is loadSpaceFromRUBE(), a function that takes a R.U.B.E. scene (in JSON format) as input and creates all needed bodies, shapes, and joints in a Nape Space instance.
var worldScale:Number = 10; // How many pixels you want each of the scene's meter to be var edgeThickness:Number = 1; // Thickness for edge/line emulation var space:Space = loadSpaceFromRUBE(__rubeSceneJSONObject, worldScale, edgeThickness);
Not all features are supported, however, due to differences in how the two engines work, and my limited knowledge of both Nape and Box2D (especially some joints). This is what my current test scene (JSON source here) looks like inside R.U.B.E.’s (awesome) simulator:
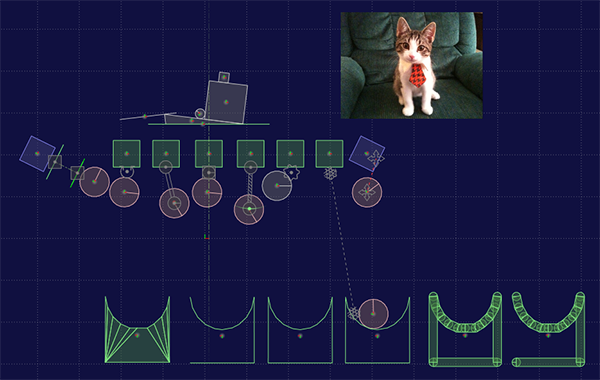
And this is what it looks like, once it’s loaded and running on my prototype:
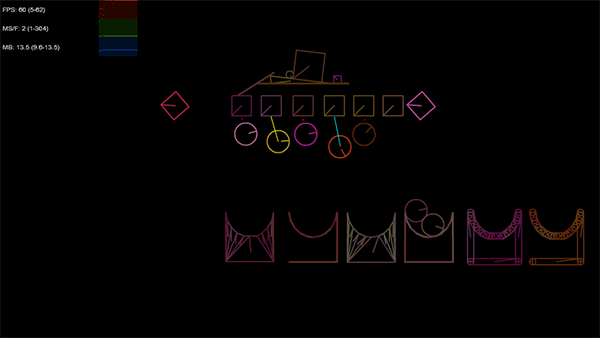
Some of the joints obviously aren’t working as expected (no support for them yet).
I will probably go this route with my prototype. Right now, this is what’s supported:
- Space and its properties (gravity)
- Basic bodies and their types (static, kinematic, dynamic)
- Fixtures/shapes (circles, polygons)
- CustomProperties (userData)
- Some joints: revolute (using a PivotJoint), distance (DistanceJoint), wheel (PivotJoint), rope (DistanceJoint), weld (WeldJoint)
- Some other joints: prismatic (using a LineJoint and an AngleJoint) (added Aug 13th)
Also, a lot isn’t supported yet:
- Some joints:
prismatic, motor (gear?), friction, pulley - Several properties of joints (limits, motor, damping, frequency, springs, etc)
Weld joints are not entirely correct (incorrect position)- Certain body attributes (mass, damping) are ignored
All physics attributes (density, friction, restitution) that are supposed to be part of a material are ignored- Certain additional shape/fixture attributes (
sensor, filters, masking, category bits) are ignored - Hex attributes are ignored (R.U.B.E. may save them, but I haven’t seen that happening yet)
And one last important note:Â Nape doesn’t support edges or chain shapes like Box2D does. Because of that, you can’t have a direct translation of certain fixtures to shapes. Instead, when a line is needed, the loader function creates a simulated line which is just a rectangle polygon shape (of thickness edgeThickness, passed in the function call) with circle shapes in its vertices as needed. This works well in most of the cases. However, if the edge is a chain shape/loop (a closed polygon), it instead creates a new, solid polygon, and subdivides it as necessary (to avoid concave polygons).
(In the latter case, if the shape fixture has a custom Boolean property called nape_isHollow set to true, instead of creating a polygon, it creates a closed line polygon).
The test scene has an example of all these situations.
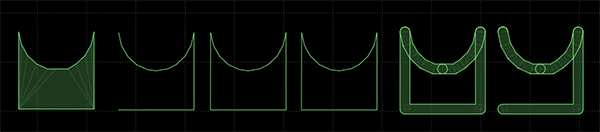
And what they look like in Nape, with an edgeThickness of 4 (scaled to 50%, and um, please ignore the circles):
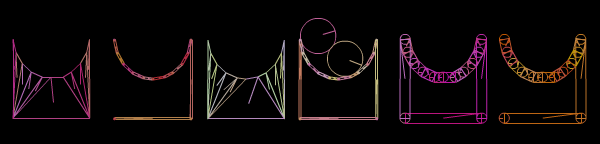
The above fixtures/shapes are, respectively:
- A polygon fixture. R.U.B.E. itself subdivides this polygon as several polygon shapes. Supported by Nape.
- A line fixture. R.U.B.E. exports this as a bunch of vectors. Not supported by Nape; the function creates line polygons.
- A loop fixture. R.U.B.E. exports this as a bunch of vectors, and attributes saying this is a loop. Not exactly supported by Nape; the function creates a single (solid) polygon and subdivides it into convex polygons.
- A loop fixture with theÂ
nape_isHollow property set totrue. Not supported by Nape; the function creates line polygons. - A line fixture with a radius of 1 (meter). R.U.B.E. itself exports this as circles and polygons. Supported by Nape.
- A loop fixture with a radius of 1 (meter). R.U.B.E. itself exports this as circles and polygons. Supported by Nape.
The reason why I’m writing this? Well, obviously the loading function isn’t working perfectly, and I wouldn’t mind any help from developers who are better acquainted with Box2D’s joints, Nape’s joints, and how they relate to each other.
Obviously I’ll continue to work on this. Any help, though – with hints, or code fixes – is more than welcomed. The source code for the load function has annotations on all features that are missing (plenty of TODO comments), so hopefully it’s not that difficult to jump in!
Update (August 13th, 2013): I’ve done a few updates to the function and it now supports a few more constraints and properties. It has some fixes as well; check the commit log for more information. And here’s a video of a scene in action in both R.U.B.E. and my game prototype loading a scene (watch in HD):
wow, that looks great! I know next to nothing about Nape or Flash, but if I can help out on the Box2D front just let me know. I see you have found my forums already 🙂
Thanks man! Things are great on editor-wise though – the JSON format documentation is great and all I need, so thanks so much for that. 🙂 I just need to properly understand the relationship between some Nape/Box2D joints and some properties to be able to properly “translate” it. Slowly getting to that…
Good, thanks!
But before i work only with box2d, and i can’t run this function on NAPE, can you share Main code?
Sorry for my english.
What problems are you having running this function?
This is what I’m doing:
1. Load the JSON file (using a simple URLLoader, or embedding it to an object)
2. Parse the JSON source (using JSON.parse())
3. Create a “space” instance:
4. Use the “space” as you would with any other Nape application (looping for step(), etc)
The code is too big to share by itself (for loading and parsing I use my AsselLibrary, creating the space instance is part of a game scene, etc), but it should be fairly straightforward as long as you can get Nape to run with an empty/test space.
Understood, working great!
Hello your good but bad support by R.U.D.E I am really mad because I want replace your level_test.json into position x y 0,0 because it shows problem because level was moved top and left that is why I want remove scene to normal and I want save from R.U.D.E What is fuck? I am really mad because liar forces “to save” Thanks I must bring police to United Kingdom. I know R.U.D.E Developer is from UK. I will ban him because not allow to force again export and save. That is crime!!!!
Alternative to R.U.D.E?????
Hi Jens,
I found the author to be helpful when I needed, so I’m sorry you had a different experience.
There are a few different editors out there that can create Box2D-based “maps”. I haven’t tried any of those, and they’re likely to use different file formats, but here’s an interesting list:
http://www.html5gamedevs.com/topic/2198-box2d-physics-editor-with-box2dweb-importer/
Thanks I have readden it. I got idea and I try it and write own nape collision editor from Adobe Air 21/22. RUBE and Physics Editor are still bugged because just generates from sprite with full collision and I try to load into Flash Player and it doesn’t show. If I use urlLoader than loader.data into JSON.parse() than scene happens to move top and left. How do I move to center of Flash Player. Just sees like bug of stage.stage width and stage.stage height. I will write bug report to Adobe.
It is okay.. No Problem sorry for delay because i am busy… Thanks